Email Alert | RSS 帮助

中国防痨杂志 ›› 2025, Vol. 47 ›› Issue (10): 1311-1317.doi: 10.19982/j.issn.1000-6621.20250166
褚光炎1, 李婷1, 于嘉宁1, 何迪1, 张堃2, 侯绍英3( ), 闫世春4()
), 闫世春4()
Chu Guangyan1, Li Ting1, Yu Jianing1, He Di1, Zhang Kun2, Hou Shaoying3(), Yan Shichun4()
摘要:
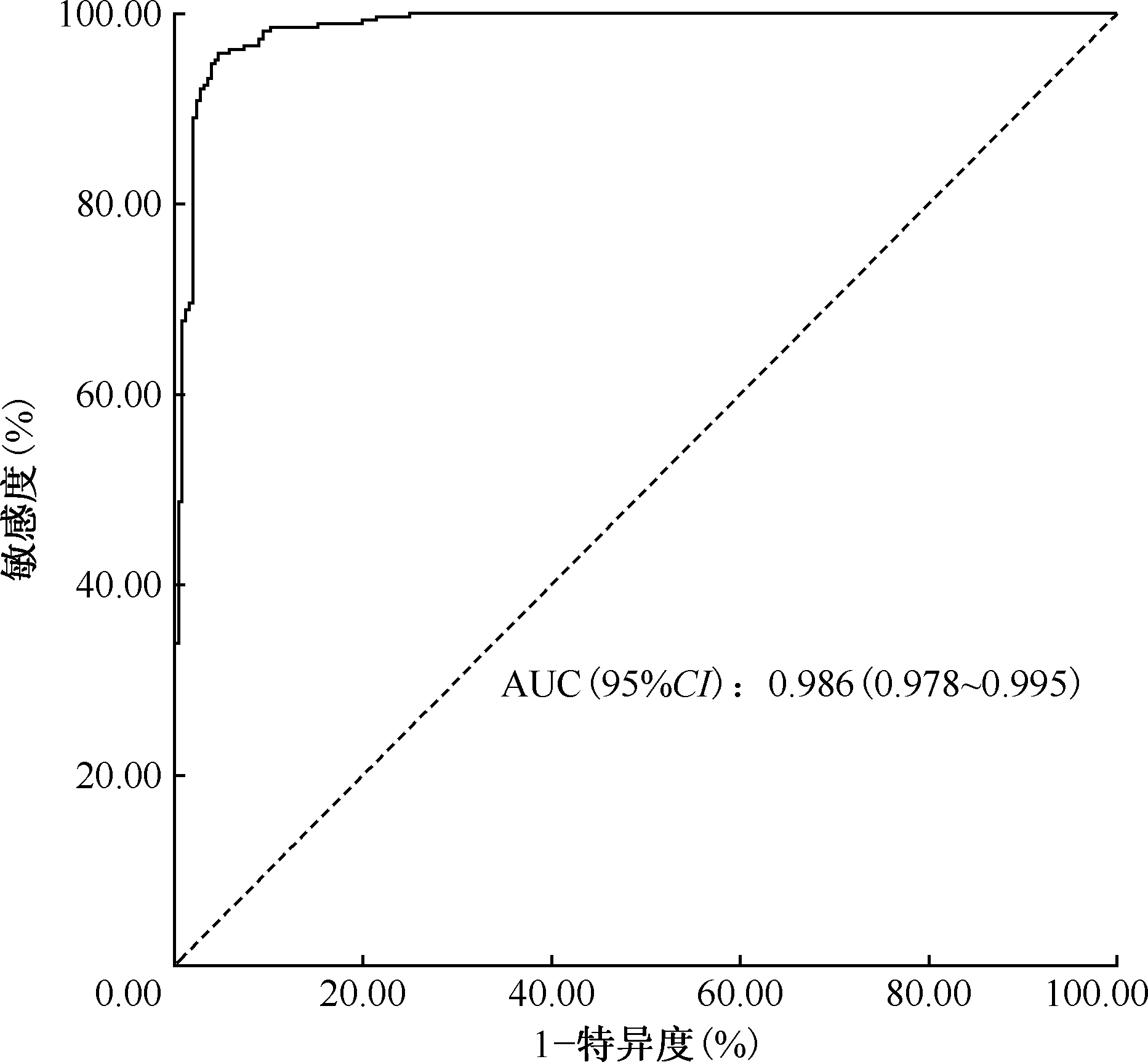
目的: 探讨随机森林模型算法对继发性肺结核的筛查价值,以期为临床早期识别继发性肺结核提供依据。方法: 收集2021年3—9月期间在黑龙江省医院健康管理中心接受体检的健康人群共1208名;以及在黑龙江省传染病院首次确诊并接受治疗的继发性肺结核患者共876例,依据纳入和排除标准,367例继发性肺结核患者纳入观察组,376名体检人群纳入对照组。收集研究对象的基本情况,按照2∶1的比例,将数据分为训练集(495例)和测试集(248例)。模型共纳入38个预测变量,使用训练集数据进行随机森林模型构建,利用测试集数据进行模型验证和评价。对模型中重要性排名前十位的变量进行两组之间的比较分析。结果: 本研究随机森林模型的最优节点数为5,决策树数目为300。模型的准确率为99.60%、精确率为99.92%、敏感度为99.20%、特异度为99.87%,其受试者工作特征(receiver operating characteristic, ROC)曲线下面积(area under curve, AUC)为0.986(95%CI:0.978~0.995)。通过基尼指数(Gini 值)平均降低量筛选出排名前十位的变量,包括血小板分布宽度(30.02)、白球比(20.70)、间接胆红素(19.32)、白蛋白(17.97)、平均血红蛋白浓度(12.24)、尿比重(11.26)、总胆红素(10.09)、总胆汁酸(7.43)、淋巴细胞百分比(6.92)、谷草转氨酶/谷丙转氨酶比值(6.50)。观察组的血小板分布宽度[15.90(15.50,16.20)fl]、谷草转氨酶/谷丙转氨酶比值[1.41(1.02,1.79)]、尿比重分布[正常27例(7.36%)、异常340例(92.64%)]均高于对照组[分别为12.00(11.10,13.30)fl,0.95(0.77,1.15),正常86例(22.87%)、异常290例(77.13%)],差异均有统计学意义(Z=-16.907,P<0.001;Z=-11.951,P<0.001;χ2=34.670,P<0.001)。观察组的白蛋白[(38.42±6.47)g/L]、总胆红素[12.80(9.10,19.00)μmol/L]、间接胆红素[7.60(5.05,11.80)μmol/L]、白球比[1.17(0.97,1.40)]、总胆汁酸[2.80(1.79,5.12)μmol/L]、淋巴细胞百分比[22.90(15.50,32.55)%]、平均血红蛋白浓度[322.00(317.00,328.00)g/L]均低于对照组[分别为(45.14±2.13)g/L,22.25(18.40,26.90)μmol/L,17.40(14.30,19.10)μmol/L,1.60(1.50,1.70),4.60(3.70,5.50)μmol/L,34.60(29.07,39.90)%,336.00(331.00,343.00)g/L],差异均有统计学意义(t=-18.891,P<0.001;Z=-14.313,P<0.001;Z=-16.994,P<0.001;Z=-17.030,P<0.001;Z=-9.675,P<0.001;Z=-12.684,P<0.001;Z=-16.843,P<0.001)。结论: 本研究构建的继发性肺结核患者的随机森林预测模型性能较好,建议进行早期筛查肺结核患者时关注一些营养指标(如间接胆红素、总胆红素、白蛋白等)变化以优化筛查策略,同时在治疗继发性肺结核患者时,注重营养治疗。
中图分类号:
 京公网安备11010202007215号
ip访问总数: ip当日访问总数: 当前在线人数:
京公网安备11010202007215号
ip访问总数: ip当日访问总数: 当前在线人数:
 本作品遵循Creative Commons Attribution 3.0 License授权许可
本作品遵循Creative Commons Attribution 3.0 License授权许可